
近日,中科軟以 “AI應用中的重點開源軟件工具和平臺建立及組織協同實施研發” 為主題,成功舉辦為期兩天的技術實踐交流會。本次活動旨在推動AI技術在垂直領域的落地應用,聚焦低成本、高精度、強安全特性,展示中科軟在垂直領域小模型研發、開源工具應用及工程化落地方面的最新成果。
本次比賽匯聚了來自中國科學院軟件研究所、中國機械工業工程集團有限公司、大家人壽保險股份有限公司、海保人壽保險股份有限公司、現代財產保險(中國)有限公司、國民養老保險股份有限公司、天津藥鏈智啟供應鏈科技有限公司、東吳人壽保險股份有限公司、中國疾病預防控制中心、陽光財產保險股份有限公司、中融人壽保險股份有限公司、中荷人壽保險有限公司、橫琴人壽保險有限公司、大家保險集團有限公司等科研機構、行業客戶及合作伙伴的專家。不同領域的專家與公司各技術團隊就如何推進AI技術在更多垂直領域的深入應用進行了熱烈討論,并對中科軟的技術成果提出了寶貴的指導意見。
AI垂直應用邁向規模化落地的關鍵窗口期 小模型與知識庫成破局關鍵
在推理成本下降與國家戰略級政策紅利的共同驅動下,我國垂直行業AI應用正進入規模化落地的關鍵窗口期。AI 技術正從通用探索邁向業務融合階段,帶來軟件開發范式的變革與應用體系的重構。企業對 AI 應用的需求逐漸聚焦于強安全、高精度和低成本,即保障數據隱私安全、滿足場景化精準計算需求、降低部署與運行成本。在此背景下,AIGC 在行業領域落地應用的重心從通用大模型轉向 “垂直領域小模型 + 專業知識庫” 的組合模式。
小模型與知識庫成為 AI 垂直落地破局關鍵,核心在于垂直場景對領域適配性、數據安全、成本控制的嚴苛要求。大模型雖具備通用能力,但在垂直領域存在隱私風險高、部署成本高、領域知識深度不足等問題;而小模型依托輕量化特性可實現本地化部署,結合沉淀了垂直領域專業知識的知識庫,能精準適配保險核保理賠、醫療診斷輔助等行業場景,解決通用技術在垂直場景中 “水土不服” 的問題,成為連接 AI 技術與行業需求的核心紐帶。
聚焦開源工具與工程化方法 筑牢落地根基
開源軟件工具和平臺在AI快速形成應用效果中扮演著重要的支撐角色。頭部ISV應熟練運用不斷迭代的開源軟件工具,包括流程框架、硬件軟件配置、外部調用方式及專項函數庫特性,尤其需關注多模態數據語義計算平臺的應用。中科軟各技術團隊在交流中展示了利用開源軟件工具和平臺作為支撐環境,在數據標注預處理、模型微調、提示詞工程優化、專業知識庫建立等環節取得的成果與實踐,驗證了垂直領域的小模型結合專業知識庫構建(如保險行業的條款解析和業務流程梳理等)能夠進一步提升AI技術與業務的適配性和落地效果。
小模型落地需具備系統化的工程方法,考驗工程化方法的可操作性、完整性和系統化方法論,包括垂直領域知識加持下的數據約束和格式、微調描述框架、提示詞規范等關鍵環節,涉及數據層、模型層、應用層的多個系統化層級:
• 數據層:規范數據約束與格式,處理多結構語料(如保險條款切分、多模態信息提取),強化基于領域知識的數據清洗與標注,加強半結構化數據集建設;
• 模型層:建立微調描述框架與提示詞規范,實現垂直模型的精準微調與推理部署;
• 應用層:支持客戶端技術遷移、組件組裝及二次開發,在 “多自由度” 工具選擇中形成收斂性落地框架,保證高質量的應用效果。
成果展示:場景化結合顯成效 團隊競技展實力
在比賽過程中,中科軟展示了其在MaaS(Model as a Service)平臺上的研發積累,包括底層資源適配、垂直模型微調推理部署以及智能助手開發等能力。今年,中科軟更加聚焦于垂直業務領域,打造精確專業的業務知識庫,并繼續優化和拓展大模型應用邊界。
經過技術成果展示與問答交流,壽險團隊的“智瞳平臺”與財險團隊的“智數平臺”案例脫穎而出。這兩個優秀案例在小模型場景適配性、開源工具應用合理性及工程化完整性等方面具備較為突出的表現。
? 壽險-智瞳平臺
保險領域的AI產品包羅萬象,如何選擇正確場景將機會轉化為產品是需要深度思考的核心問題。在IT部門推動 “提升國產開源軟件占比” 與業務部門期望 “加速智能化轉型、降低人工錄入錯誤率” 的雙重需求背景下,兩個部門目標的融合,為智瞳平臺的誕生與發展提供了堅實基礎。
為確保平臺有效落地,團隊對現有開源產品進行了深入調研與對比。結果顯示,國內主流開源產品中,大部分AI開源模型在通用場景表現尚可,但在保險業務領域卻存在不足。具體體現在識別準確率偏低、大尺寸圖像內容識別不全、復雜表格信息粘連等關鍵問題上。
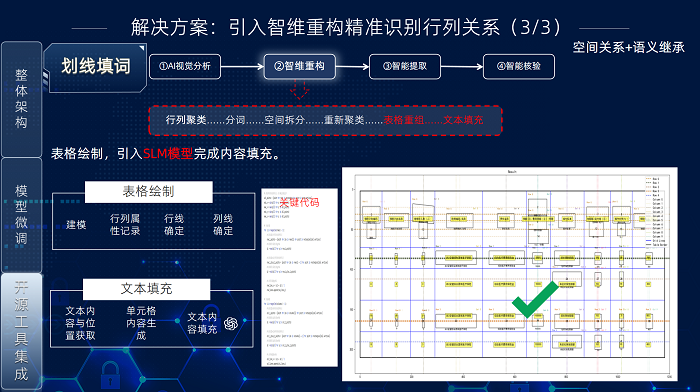
針對這些挑戰,智瞳平臺制定了“領域知識注入 + 工程化深度優化” 的針對性解決方案。平臺整合OCR和SLM小模型,搭建了平臺的基礎部分,包含視覺分析、智維重構、智能提取和智能核驗等功能,為核心系統提供非結構化輸入和查詢能力。后續隨著更多對接,可以將非結構化能力,輻射到壽險領域內其他系統,助力公司實現智能化轉型。
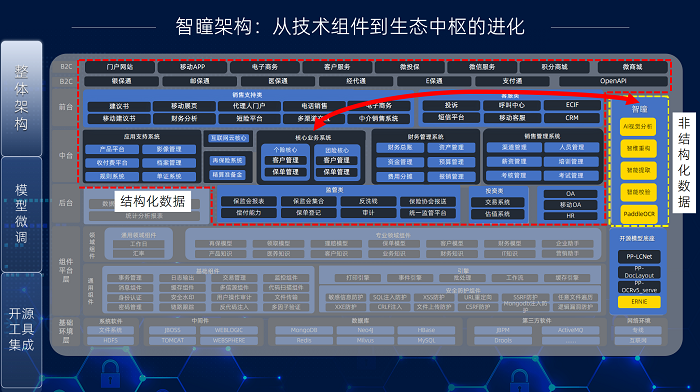
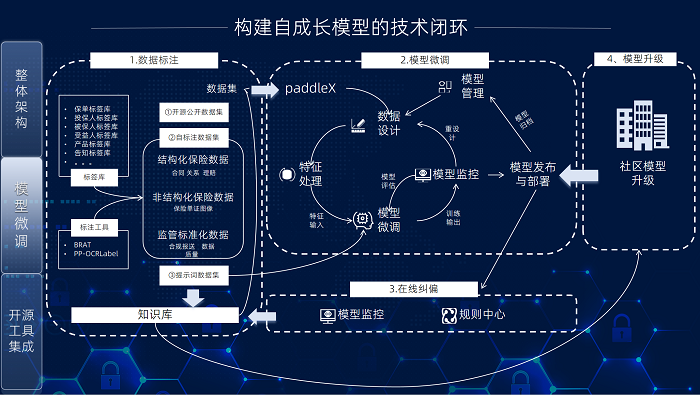
針對上述開源方案在實際集成中的關鍵能力缺口,在落地應用環節引入了‘智維重構’作為核心補充。該方案特別強化了對復雜版面結構(尤其是無邊框表格)的解析能力,并有效解決了視覺粘連導致的識別歧義問題,從而在整體上提升了集成解決方案的魯棒性和信息抽取精度,確保了業務需求的有效滿足。
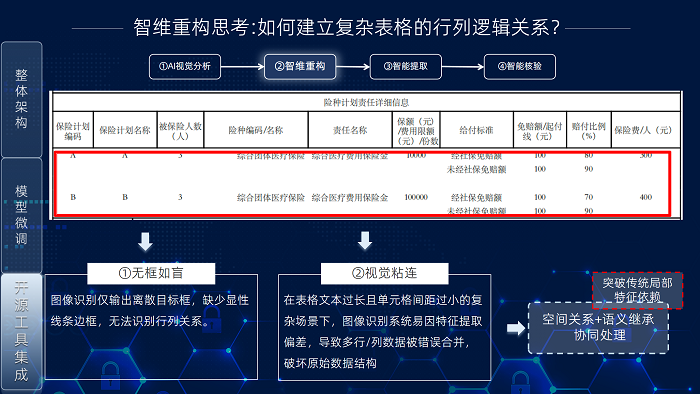
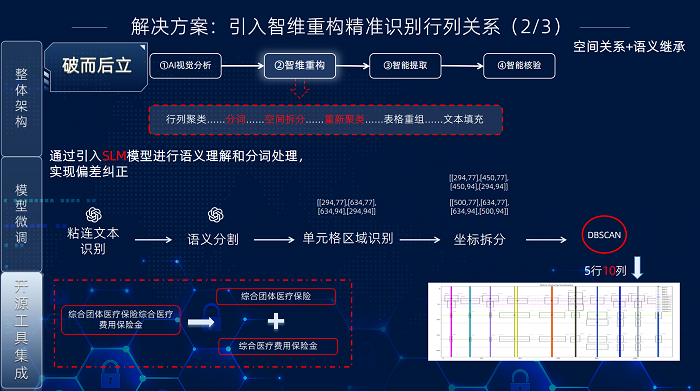
“智維重構”方案解決無邊框表格識別和視覺粘連問題,其核心流程包含四步:行列聚類、粘連文本分割、表格重組和文本填充。
行列聚類是第一步,旨在將識別引擎輸出的離散、無序文本框組織成潛在的行列矩陣。團隊采用DBSCAN密度聚類算法,因其能有效處理不規則分布和噪聲(如文本框疏密不一、缺失或錯位)。聚類依據文本框的幾何中心點空間特征。DBSCAN的核心參數鄰域半徑 (Eps) 定義了判斷文本框是否同屬一行/列的距離閾值。算法分析中心點密度,自動將鄰近文本框聚集成簇,形成行列分組。
此步驟將離散文本框初步組織成結構化行列矩陣框架(如成功識別出5行x11列矩陣雛形),為后續重構奠定關鍵結構基礎。
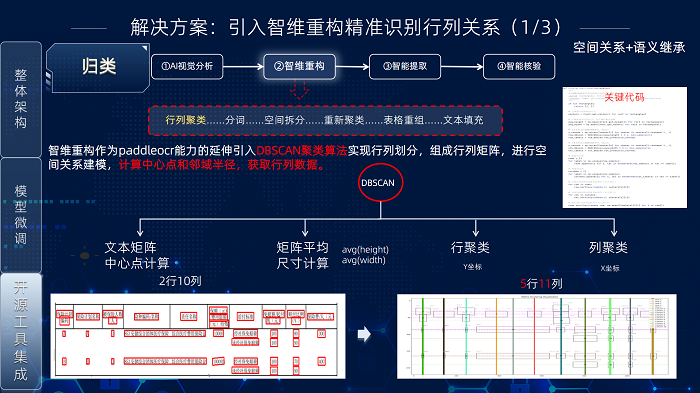
粘連文本分割步驟解決因字符間距極小、筆畫重疊或背景干擾導致的文本粘連問題(即多個單元格內容被錯誤合并為一個文本框)。為此,團隊引入基于深度學習的語義分割模型(SLM),對行列聚類后的區域進行精細化處理:
識別粘連區域: SLM 依據語義和視覺上下文,精準定位行列矩陣中的不合理粘連區域。執行語義分割: 對粘連區域進行像素級分割,在視覺和語義層面精確區分粘連文本。
拆分與重定位: 根據分割結果和原始坐標,將粘連文本塊拆分為獨立的單元格文本單元,并生成精確的新邊界框。
分割完成后,系統觸發受影響區域的重新聚類,確保新拆分的文本框被正確融入原有行列結構,形成校正后、結構完整且邊界清晰的行列矩陣。
在數字化浪潮下,人工智能(AI)與商業智能(BI)技術的迅猛發展正推動眾多企業加速邁入自助式數據分析的新階段。然而,在這一過程中,企業仍面臨著諸多挑戰,如分析門檻高、被動接受需求導致的需求響應周期長、分析深度不足等問題,這些問題在保險行業尤為突出。作為數據密集型行業,保險行業擁有海量且復雜的業務數據,但傳統的數據分析方法難以充分挖掘這些數據的潛在價值。因此,中科軟憑借在保險行業的深厚積淀和對人工智能技術的深入研究,構建了一個面向保險行業的數據分析智能體平臺——智數平臺,旨在解決保險企業在數據分析過程中所面臨的難題,提升數據分析效率和質量,助力保險行業的數字化轉型和智能化發展。
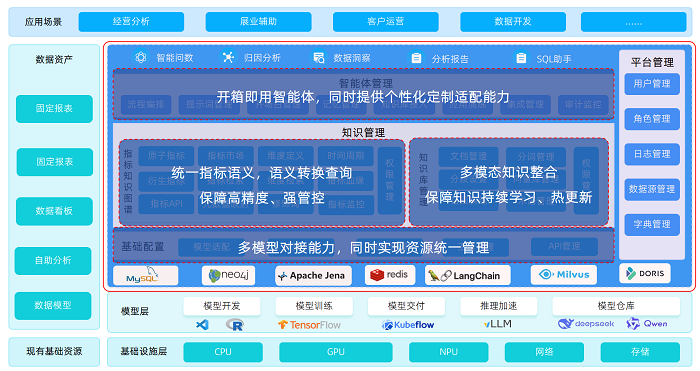
智數平臺(idata)基于微服務架構和開源技術棧(Langchain4J+Milvus)構建,平臺聚焦四大核心模塊:指標知識圖譜管理、知識庫管理、智能體管理以及平臺基礎配置,核心功能如下:
知識管理:包括指標知識圖譜及知識庫管理兩大模塊。其中指標知識圖譜管理,主要包括指標定義、維度定義、指標血緣、元數據映射及權限管理等功能,實現指標的語義統一以及語義查詢的轉化,以保障數據的高精度和強管控;知識庫管理主要包括文檔知識庫管理、向量庫管理、術語管理、分段管理及召回演練等功能,實現了多模態知識整合,支持知識的持續學習和熱更新,同時打通了指標知識圖譜與知識庫管理的雙向互動。
智能體管理:智能體構建平臺主要包括流程編排、記憶管理、知識庫接入及對外集成等功能。除提供開箱即用的數據分析智能體之外,還具備個性化定制適配能力。
多模型適配能力:智數平臺采用開放式AI架構,全面兼容主流云服務大模型(如DeepSeek、文心一言、Qwen系列等)及企業私有化部署模型,在確保數據安全合規的同時,為保險業務場景提供最優的AI分析能力支撐。
在數據分析智能體的構建與應用中,平臺沉淀出以下最佳實踐,形成可復用的方法論體系:
• 統一語義管理,通過指標管理模塊建立標準化語義體系,提升分析準確性、可解釋性與可比性

保險行業存在著大量的專業術語和領域指標,這些術語和指標在不同的業務場景和數據源中可能會有不同的表達方式,這給數據分析帶來了很大的困難。依托中科軟30年深耕保險行業所積累的豐富領域知識,通過將這些領域知識與人工智能技術相結合,智數平臺通過指標管理模塊實現統一語義的管理。通過指標管理,智數平臺對這些術語和指標進行了標準化和統一化處理,建立了一個清晰、一致的語義體系,不僅提高了數據分析的準確性,還增強了數據分析結果的可解釋性和可比性。
• 知識內容熱更新,實時轉化指標與對話信息,保證知識信息的質量和時效
傳統開源知識庫管理工具依賴于手工上傳文檔進行更新,為了提升知識更新的及時性和準確性,平臺對現有的開源知識庫管理工具進行優化升級,實現知識的實時熱更新,極大地提高了知識更新的效率,減少人工干預的繁瑣流程,降低人力成本和時間成本。通過自動化的更新機制,可以有效避免因人為疏忽導致的信息不一致問題,增強知識庫內容的準確性和可信度。實時更新機制能夠確保知識庫內容始終與企業的實際業務數據保持同步,為員工提供最新、最準確的知識支持,從而提升企業的整體運營效率和決策質量。
• 多路知識檢索,融合KV精準檢索與向量檢索,精準理解業務語義,高質量召回領域知識
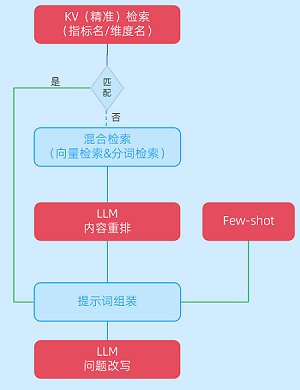
基于對數據分析場景用戶問數行為的深入分析,發現約30%的查詢中涉及的指標或維度表述相對精準,在知識召回策略上進行了優化設計:
優先采用KV精準檢索機制,當用戶查詢中的關鍵要素(如指標名、維度名)能夠與知識庫中的詞根、術語完全匹配時,直接召回對應的結構化知識內容;而對于表述不夠完整或模糊的查詢,則啟動混合檢索模式,結合向量檢索和分段檢索等方式進行擴展召回,確保最大程度覆蓋用戶意圖。
通過多模態知識存儲、多路檢索策略、語義理解增強和生成優化等技術創新,顯著提升了保險數據分析的檢索效率和語義理解精準度。
整個流程形成了從問題理解到知識檢索再到內容生成的閉環優化體系,既充分利用了結構化知識的確定性優勢,又通過大模型的語義理解能力彌補了用戶查詢的不完整性,最終實現了保險數據分析場景下高精度、高效率的智能數據查詢。
• 基于指標體系的轉義路徑,將自然語言需求自動轉化為指標查詢語言(MQL)及SQL,實現語義的精準轉化
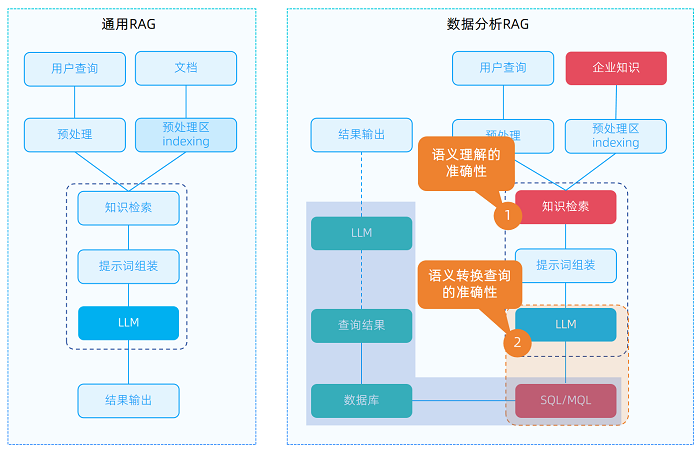
數據分析的智能體,最終都會同數據庫進行交互,進行指標數據的查詢。借助大模型的能力以及自身指標模塊的能力,平臺實現了從內容檢索結果到MQL生成,再到SQL生成的完整流程路徑。該流程通過結合大模型的語義理解能力和指標管理模塊的精確控制,來提供安全、高效的數據查詢服務。
這一模式的核心在于將自然語言處理技術與保險行業的專業語言體系相結合,使用戶能夠以自然語言的方式表達數據分析需求,而平臺則能夠自動將其轉化為指標查詢語言,并進一步轉換為數據庫查詢語言,從而實現對保險數據的高效查詢和分析。這種路徑在保證數據安全有效管控的前提下,不僅降低了數據分析的門檻,使非技術人員也能夠輕松地進行數據分析,而且在數據庫查詢過程中,根據指標熱度情況進行預計算處理,有效提升數據查詢的準確性和效率,能夠快速響應保險業務中的各種復雜查詢需求。
未來展望:打造廣義行業應用軟件 深化垂直領域AI應用
本次比賽的成功舉辦,不僅促進了中科軟不同團隊間在AI應用領域的技術成果交流,還加強了與客戶、合作伙伴和研究機構的溝通。參與評審的專家對中科軟的技術成果給予了充分肯定,并對公司加大各解決方案的落地力度,推進技術與業務的深度融合,早日釋放更大業務價值提出了更高的期望。
未來,中科軟將充分發揮領域知識與工程化實施經驗等優勢,持續深化垂直領域小模型應用,聯合上下游伙伴,共同服務客戶,支持遠端大模型與本地私有化小模型對接,融入多模態知識庫管理,結合提示詞工程、數據集建設等能力,推動AI與核心業務系統群等已有應用軟件的融合,擴展為廣義行業應用軟件系統群,幫助行業客戶在保障信息安全的前提下,實現更高效、精準的AI落地能力。